One issue I ran into while working on the chord generation model was the issue of the vocabulary size of the tokenizer needing to be bigger. Because so, while the model was reducing the loss relatively well (currently, the loss is at around .10), it was not improving in an alternative metric I use to evaluate the quality of the model; counting the number of jazz chord progressions within the generated text (251s).
That was a result of a few data augmentations I’ve done with the training data, which multiplied the variety of chords to a large extent; Transposing a tune into many different keys increased the dataset by about 12-fold. I believe the transposition work to be an important part of training the model since that will allow the “vocabulary” of the model to be more flexible and allow for greater expression.
Chords can have varying complexity; It’s important to know where the complexity comes from: - Number of notes that are being played. Chords with 3 notes are generally perceived as simpler than larger “voicings” with 6 or more notes. - With more notes, you choose different chord combinations with slight variations in pitch which result in more tension sonically.
For example, a C dominant chord (a C major chord with a b7), can be expressed in many different ways.
- The most basic way with played notes: C, E, G, Bb or as notation: C7
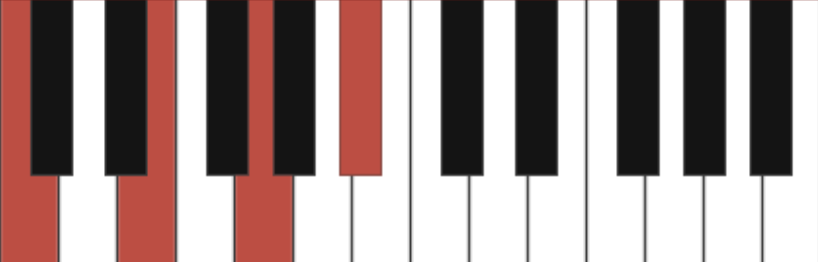
- A more advanced way with played notes: C, E, G, Bb, Db or as notation: C7b9
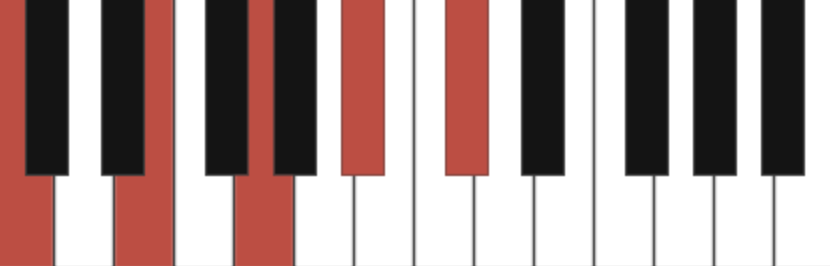
- Slightly more complex with played notes: C, E, G, Bb, D, F or as notation C11 (this is also)
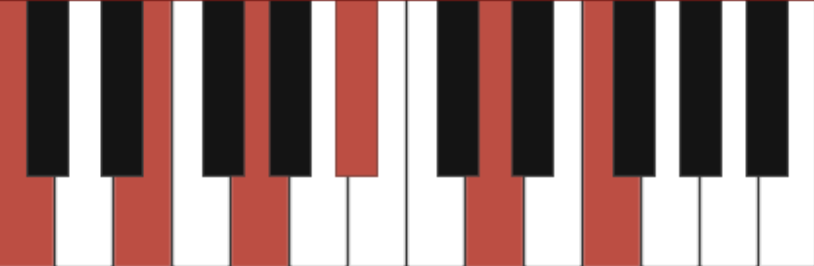
By adding more notes, and changing the pitch by a half-step down/up, you can achieve more varieties of the same type of chord. With that in mind, I built an encoder/decoder that will interpret the basic characteristics of the chord (the root note, and whether a chord is minor, major, or dominant) to simplify the dataset.
Simplifying the vocabulary allowed me to build out a model that produced chord progressions with relative ease.
One other benefit is that when structuring compositions, musicians don’t necessarily need the complexity right away; they’d prefer to start with something more high-level and simple and build on the complexity on their own.
Additionally, I’ve tried combining the simplified dataset with the original and generated more data this way. But this strategy has not been successful so far because the sheer number of tokenized data hasn’t necessarily decreased. One question I have is whether the model itself will understand the similarities between two vocabulary tokens C7 vs C7b9. Perhaps if I can introduce complexity in a more gentle way, the model will have an easier time understanding the chord progressions.
Alternatively, I could use a multivariate LSTM to encode various aspects of the chord. Each chord could be represented like so:
[Chord Root, Chord Type, Additional Chord Metadata]
[C, 7, b9]
In conclusion, mixing complex and simple chords wasn’t as effective as I wanted it to be in my experiments. One course of action I might take is to start with simpler processed chords and introduce complexity bit by bit. Another more aggressive refactor may be to convert the LSTM model into a multivariate LSTM that can express chord qualities in a more dynamic way.