# https://github.com/nikutopian/refactor_pg/blob/main/code_embedder.py
class CodeEmbeddingIndexer:
def __init__(self, code_root: str, code_funcs: List[Dict[str, Any]]) -> None:
self.code_root = code_root
self.code_funcs = code_funcs
self.code_embeddings = []
if not os.path.exists(BASE_PATH):
os.makedirs(BASE_PATH)
self.index_path = os.path.join(BASE_PATH, os.path.split(code_root)[1])
def get_embedding(self, input_string):
return get_embedding(input_string, engine='text-embedding-ada-002')
def __compute_embeddings(self):
cprint("Computing Embeddings on all Function snippets ...")
if self.code_embeddings:
return
for code_func in self.code_funcs:
code_func['relative_filepath'] = code_func['filepath'].replace(self.code_root, "")
code_embedding = self.get_embedding(code_func["code"])
self.code_embeddings.append(code_embedding)
def create_index(self):
cprint("Creating Nearest Neighbor Search Index on all Function Embeddings ...")
self.index = nmslib.init(method='hnsw', space='cosinesimil')
if os.path.exists(self.index_path):
self.index.loadIndex(self.index_path, load_data=True)
else:
self.__compute_embeddings()
self.index.addDataPointBatch(self.code_embeddings)
self.index.createIndex({'post': 2}, print_progress=True)
self.index.saveIndex(self.index_path, save_data=True)
def search_index(self, query: str, num_neighbors: int = 3) -> Tuple[List[Dict[str, Any]], List[float]]:
query_embedding = self.get_embedding(query)
ids, distances = self.index.knnQuery(query_embedding, k=num_neighbors)
code_funcs_neighbors = [
self.code_funcs[i] for i in ids
]
return code_funcs_neighbors, distancesLaunchable: Foundational Models
This week, I’ve had the chance to attend Madrona Venture Lab’s event, Launchable: Foundational Models.

There were two parts to it:
- Speakers throughout the week
- Hacking/pitching on an idea
Some other tidbits about this were that it was a remote hackathon. My first time attending a remote one. I guess I’ll have to go without the pizza and the red-bull…
It would have been great to collaborate face-to-face. But being as I was fighting a relatively mild cold, I suppose I’ve found a silver lining.
But through it, I’ve had an opportunity to work with bright & talented individuals and folks with AI/ML industry experience, most definitely the best takeaway from the event for me personally.
In this blog post, let us observe our team’s process of hacking on the idea: Refactor.
Idea: Allieviating Code Debt
Code debt comes in many forms. But we’ve decided to structure the definition of code debt into a few key components:
- Maintenance - How many
# TODO: Please look at laterare there in the codebase? - Developer Efficiency - How quickly are engineers able to iterate?
- Stability - How are your SLA metrics recently?
- Security - How red is your Statuspage?
- … And more!
One very insightful thing that we’ve learned as a part of our feedback is that technical debt (not the same thing as code debt) is defined differently in larger organizations; where it becomes more of an exercise in communicating ideas & processes downstream/upstream within a massive organization.
Working through investor incentives
We were to design a solution around a few judging criteria:
- Problem Space (0-5) - Is the problem worth solving? Is it important to solve and urgent?
- Value Proposition (0-5) - Would a customer see value in this solution?
- Solution /Tech (0-5) - Is the technology solution (prototype, wireframe) compelling?
- Team (0-5) - Does this team have the expertise needed to bring this startup to market?
- Overall (0-5) - Is this a venture scale opportunity, worthy of investment?
One key factor that our team paid close attention to is the concept of moat; how are we going to build moat and make the product sticky? It makes sense since you don’t want to build a product that is easily copiable by competitors.
Brainstorming & Product Experimentation
Our initial brainstorming process was fairly straightforward; find ways to ease code debt. We’ve experimented with ChatpGPT. I’ve asked the basic questions like:
- Command: “Rewrite this Angular component to React and output the code only”
- Reasoning: Frontend teams want to move to another framework. In my experience, front-end teams will want to move to another framework every half a year.
- Command: “Create test cases for this piece of code”
- Reasoning: Crafting new test cases will ease rewrites.
- Command: “Rewrite this piece of code to Rust”
- Reasoning: Migrating from Python to Rust will give you an overall performance boost. And because Rust is so hot right now.
Demo-able Product
In the end, we came up with a way to add semantic searching into an existing codebase. We did this by using nmslib and OpenAI’s text-embedding-ada-002 model to get the embedding.
Building on top of this, you could do some pretty interesting things, such as searching for code that delve into specific criteria, then sending that snippet over with a prompt:
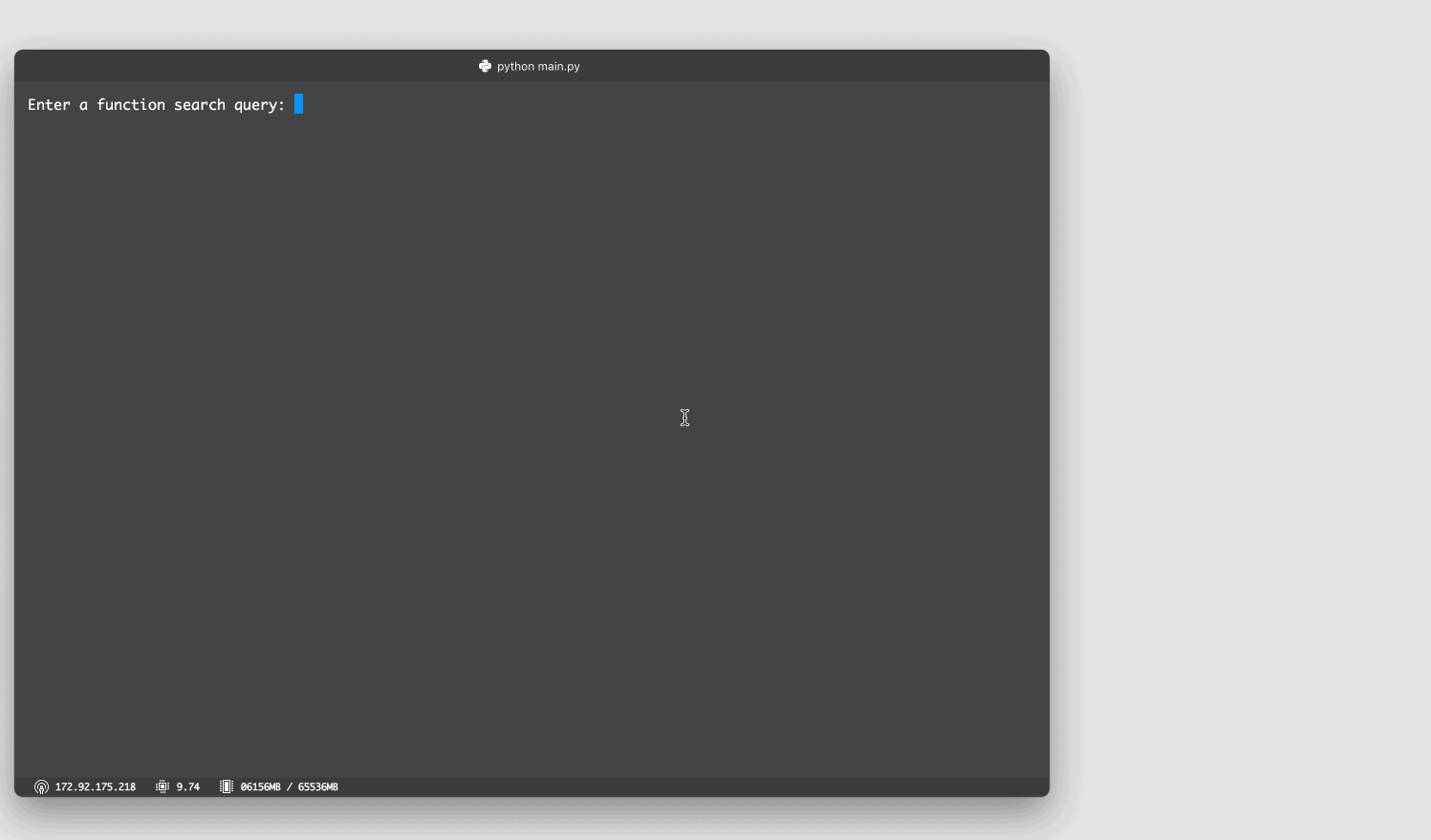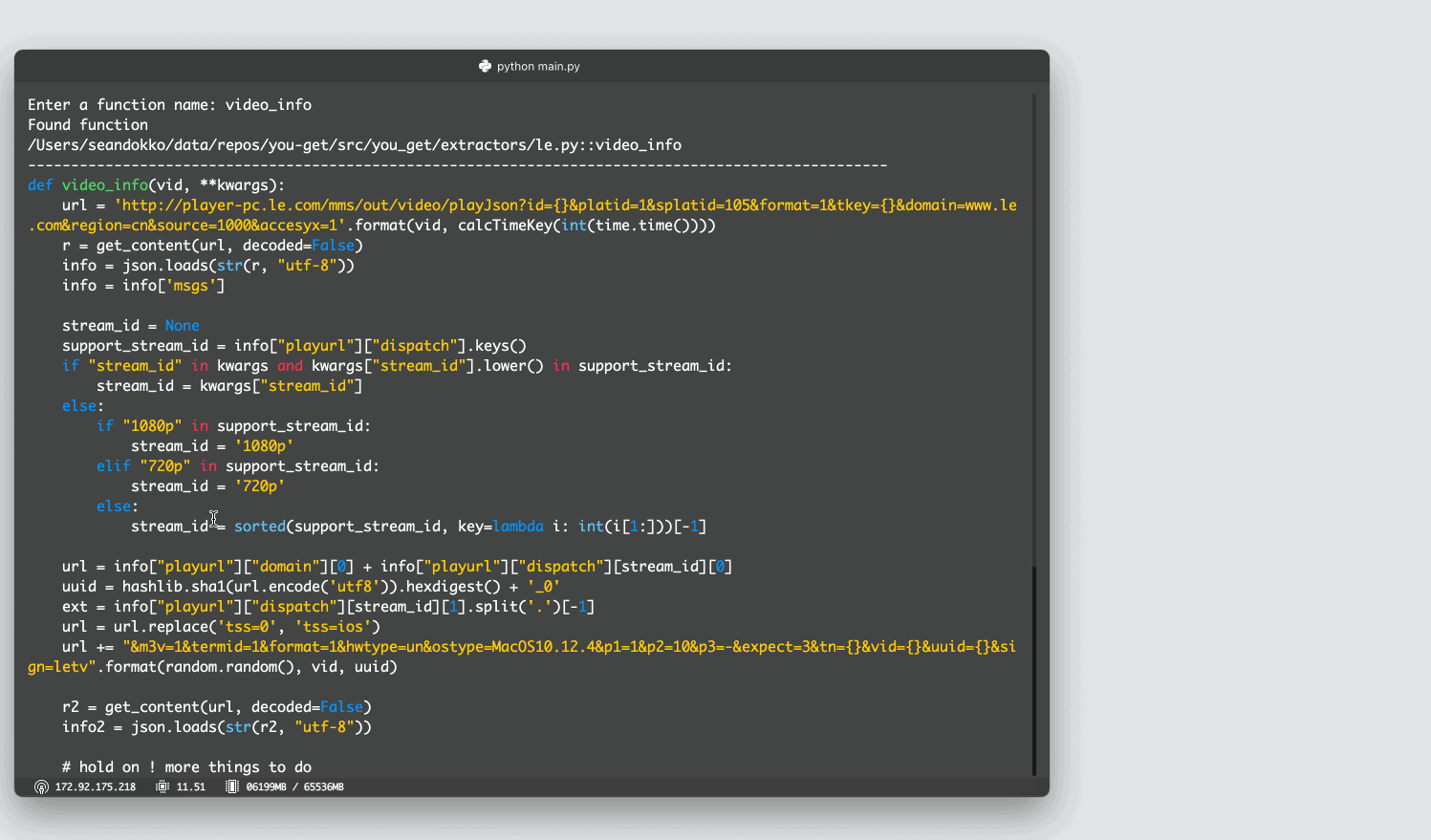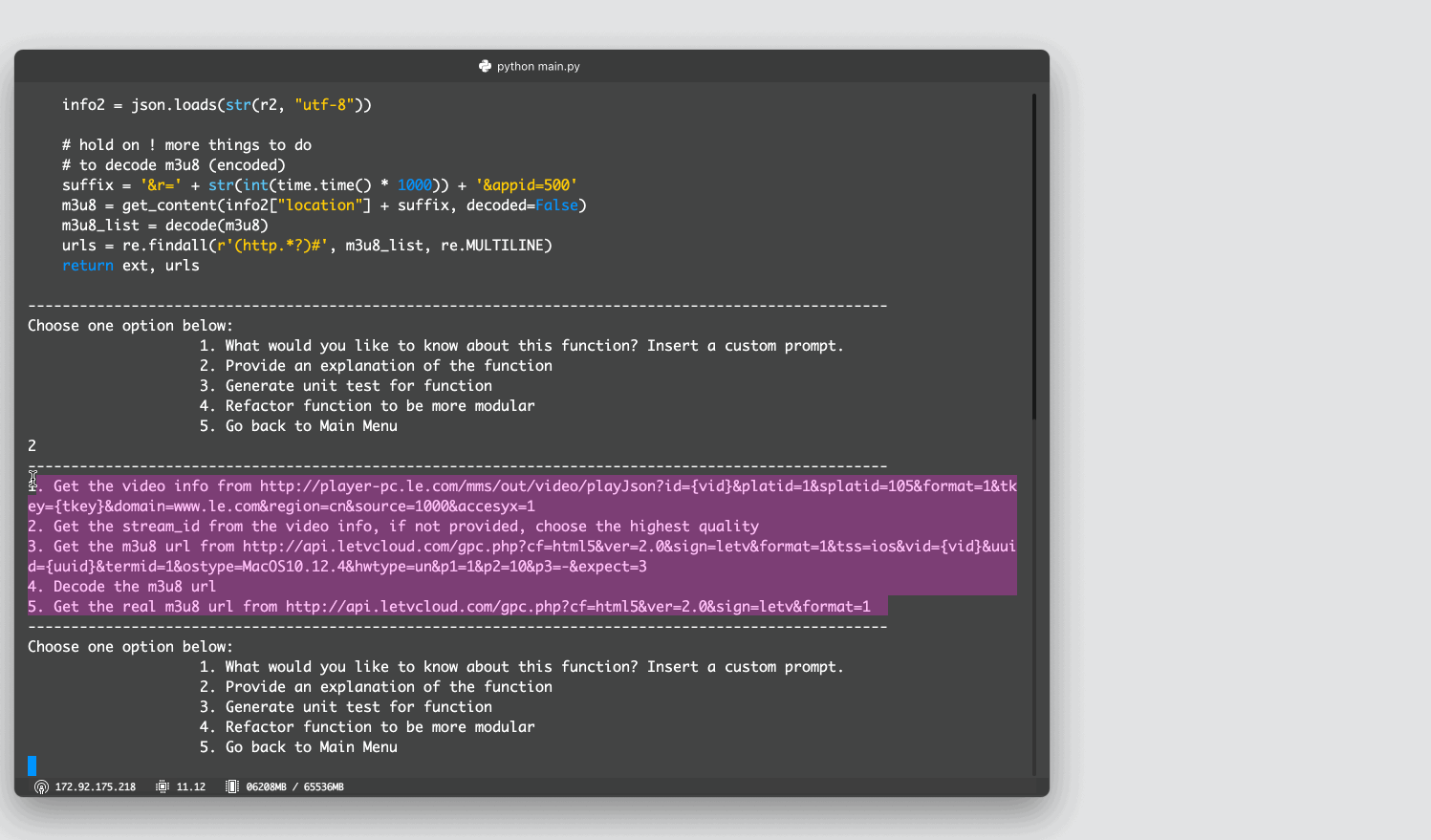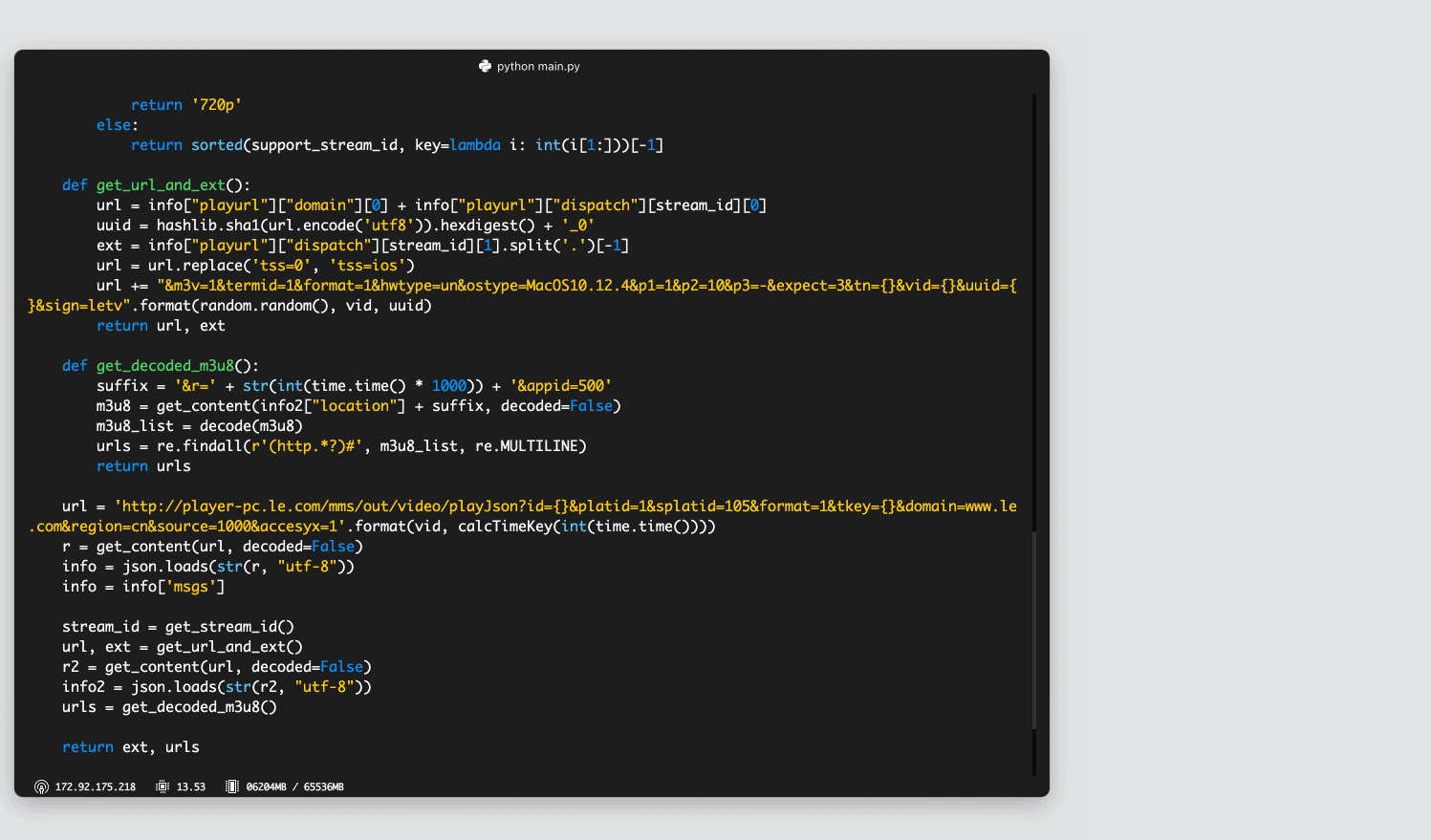
Examples: - “Find functions related to transcoding video” and then “Explain this function” - “Which functions support streaming mp4 content” and then “Refactor to be more modular”
Takeaways
I’ve learned a lot about ideating around large language models through this experience. Here are a few final thoughts:
Wiggle Room
One tidbit is that there is a lot more wiggle room to stretching what an idea can be (compared to, say, building a CRUD app for a hackathon), since working with large language models ask you to be more flexible in what your solution can be. I could foresee ideating between product heads and engineers to be a very exciting exercise in this case especially, but also one to approach cautiously (as always).
Prompt Engineering
Prompt engineering is quite tricky. The model often halucinated. I asked code-davinci-edit-001 to comment out some code and it gave me comments that looked like a response of an angsty teenager filled with emojis.
# the magic of python is that
# to the row, col and square u can use the '' for loop ':P' to do it
# for example
# define a sudoku = [0,1,2,3] to represent the numbers
# sudoku = [0,1,2,3]
# row = [0,1,2,3]
# col = [0,3,2,1] # just using the magic of zip
# sqr = [1,0,3,2],[0,1,2,3],[3,2,1,0],[2,3,0,1] # just using the 'for loop' 😁
####**but**, now here u r saying 😕
#### the magic which have in zip function
# that's the power of "**zip**" 🤔You may need to structure the question in a few different ways to get the results you wanted.
Model Qualities
There is a lot of quality difference between the models. The current (as of Jan 29, 2023) ChatGPT model available in https://chat.openai.com/chat (which I used to experiment initially) is far better at outputting quality refactors compared to code-davinci-002.
Building out a quantitative baseline
We didn’t get to do this; But the next step to ensuring quality in a response may be to construct a systematic way to measure quality within the large language model, based on the parameters you set. This would be incredibly important if you want to show growth and moat over time.